Overcoming Testing Issues in Hourly Phishtank URL Data Synchronization
Testing hourly Phishtank URL data synchronization is a complex task that can be made or broken by your security infrastructure. This manual assists cybersecurity engineers, QA teams, and DevOps experts in overcoming the complexities of testing while processing thousands of phishing URLs per hour.
Real-time URL data feeds require bulletproof testing methodologies, but customary techniques frequently fail when presented with Phishtank’s dynamic data sets. Teams grapple with everything from managing API rate limiting to ensuring data integrity across multiple platforms.
We’ll look into how to develop strong test frameworks that can process high-volume URL validation without compromising your system. You’ll learn effective monitoring methods that detect synchronization failure before it affects your security posture, along with performance optimization tactics that keep your tests running efficiently even when peak data loads strike.
Phishtank URL Data and Synchronization Requirements
Real-time threat intelligence requirements for QA teams
Today’s QA professionals work in an environment where time is of the essence. As soon as a brand-new phishing URL is available, the attackers can steal credentials, pilfer sensitive information, or spread malware within minutes. Security operations centers require real-time access to the freshest threat intelligence to secure their organizations efficiently.
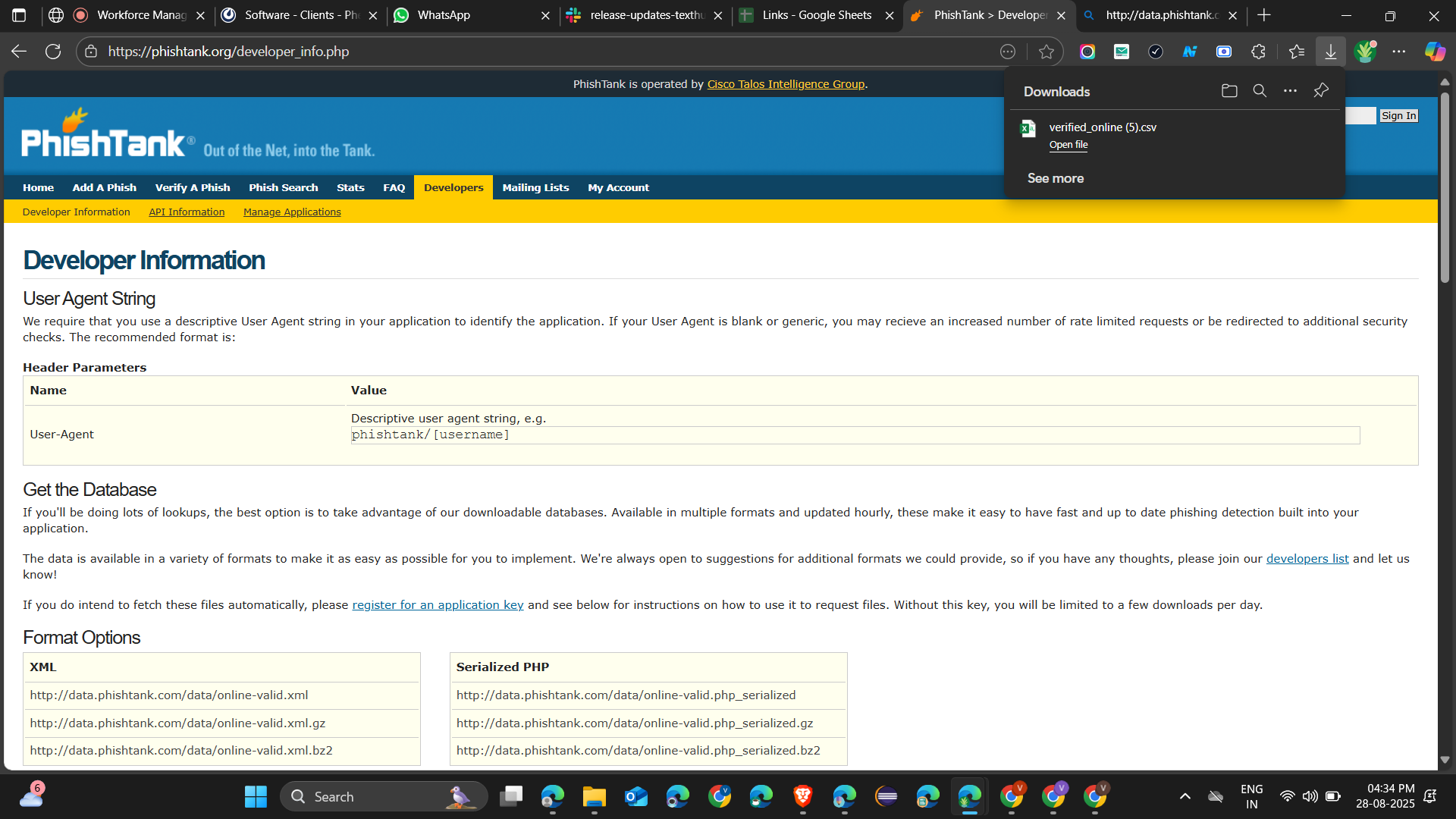
Phishtank is a community-based system in which security experts publish newly found phishing URLs. This crowdsourced data is priceless when used within security appliances, provided it arrives quickly enough to be relevant. Teams need current information on which to base their email security gateways, web filters, and SIEM systems before users reach malicious content.
The test goes beyond merely getting new threats. Timeliness and quality of data require confidence among security analysts. Outdated threat intelligence leaves gaps in protection, and complex phishing campaigns may evade defenses. Teams have to maneuver between taking action on unsubstantiated submissions and waiting for verification, and data freshness becomes a key ingredient in their decision-making.
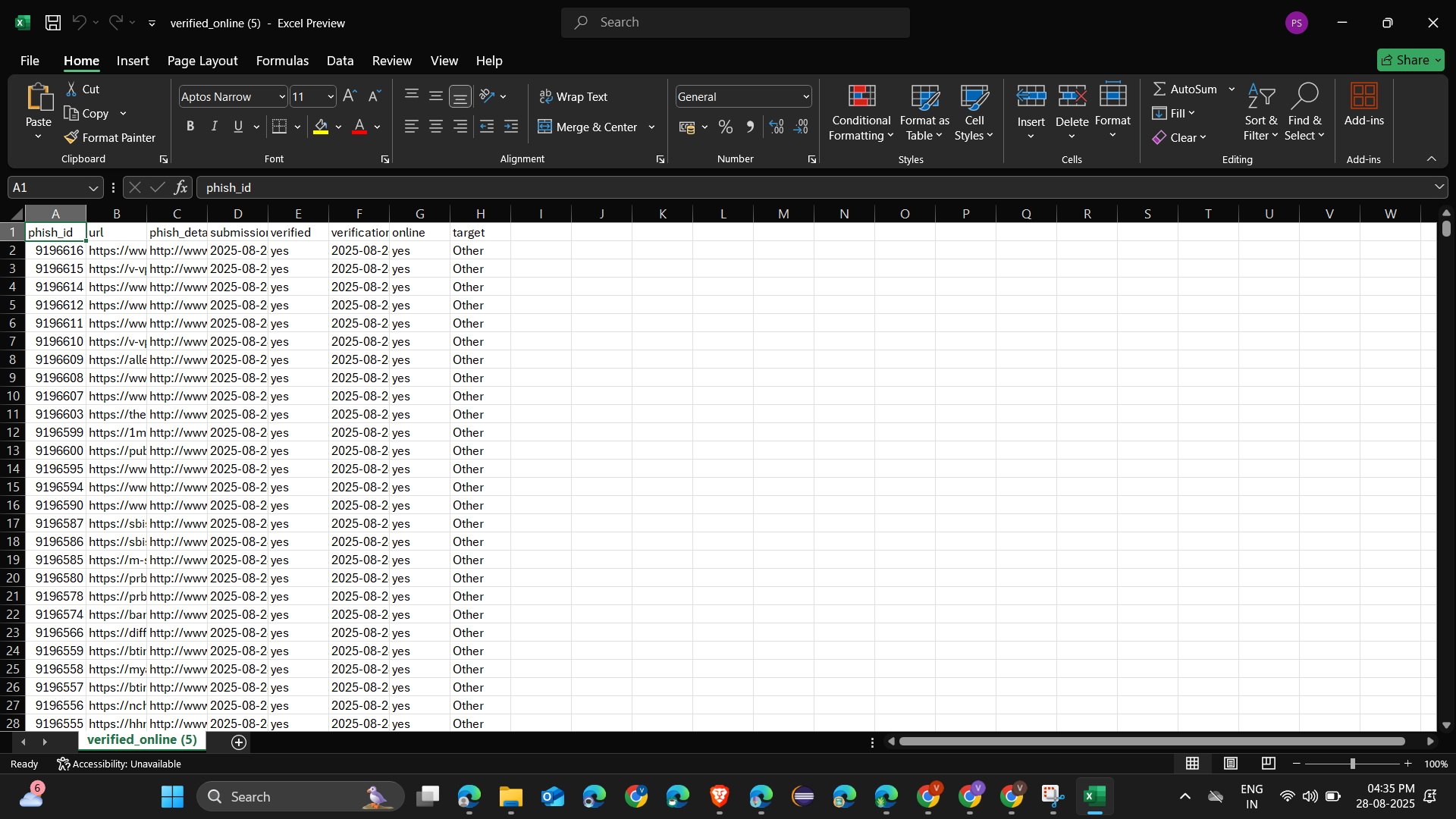
Hourly data refresh cycles and their effect on protection efficiency
Synchronization cycles of an hour create a tenuous balance between system responsiveness and protection coverage. Though greater frequency of updates would in theory mean better protection, they would also raise the load on infrastructure and likely cause system instability.
The one-hour window is a compromise most organizations have to live with, but during active phishing campaigns, the time seems to drag like an eternity. Attackers usually act with temporary URLs, running campaigns that can do their work in the synchronization window.
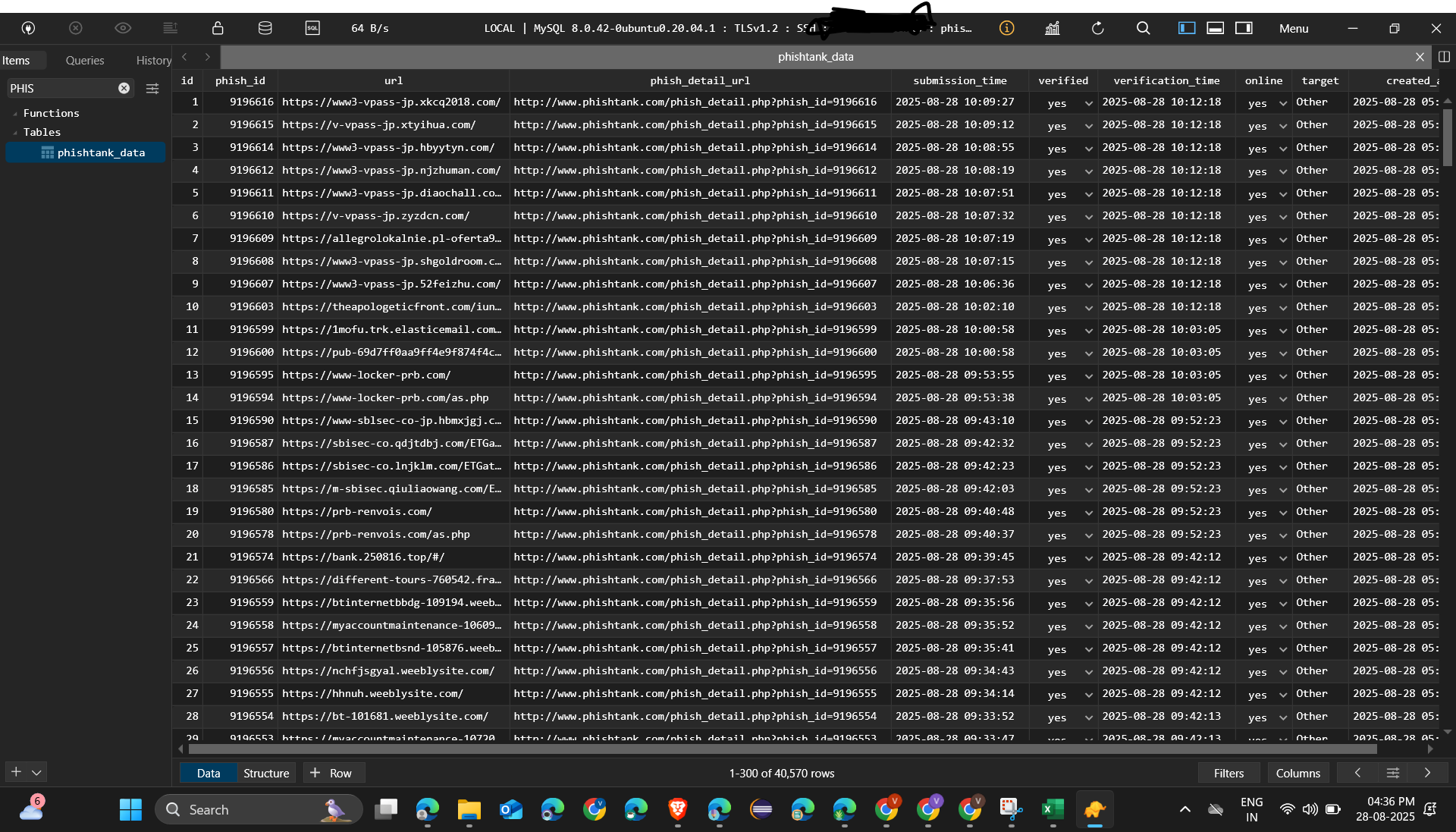
Consider the typical phishing attack lifecycle:
| Attack Phase | Duration | Risk Level |
|---|---|---|
| Initial URL deployment | 0-15 minutes | Critical |
| Peak victim targeting | 15-45 minutes | High |
| URL detection and reporting | 30-60 minutes | Moderate |
| Synchronization to security systems | 60+ minutes | Low |
This timeline illustrates how the hourly cycles can overlook the deadliest phase of an attack. Organizations that conduct hourly syncs need to complement their defenses with additional detection mechanisms, including behavioral monitoring and real-time URL reputation inspections.
Volume and velocity issues of handling large URL datasets
Phishtank’s database holds hundreds of thousands of URLs, with thousands more added each day. Working through this amount in short time frames presents substantial technical requirements for synchronization systems.
Each URL record contains several data points: submission time, verification status, target data, and geolocation data. Systems need to download, parse, verify, and merge this information without compromising data integrity. The magnitude of these datasets can overwhelm networks and storage systems not optimized for bulk data handling.
Velocity introduces another dimension of complication. New submissions are constantly coming in within every hour, presenting a target for synchronization processes to chase. Systems need to process partial updates, duplicated entries, and out-of-order information while avoiding any genuine threats.
Memory management is essential while handling huge datasets. Populating memory entirely with URL lists to process them could drain system resources, and streaming methods could degrade validation and integration processes. Achieving the ideal balance demands detailed planning on architecture and proper testing.
Timing constraints essential for accurate threat detection
Timing limitations of URL data synchronization directly affect an organization’s ability to recognize and stop threats. Failure to observe a synchronization window or delayed execution can expose networks to ongoing phishing attacks.
The most significant timing limitation is data staleness tolerance. Malicious URLs identified should be blocked in real time, but false positives can interfere with legitimate business processing. This creates a need to reduce processing time without compromising data validation quality.
Network connectivity problems exacerbate timing problems. Occasional connections, bandwidth constraints, or outages in service can cause synchronization cycles to be slowed. Systems are required to cope with such situations gracefully, using retry logic and fallback procedures without sacrificing data integrity.
Database performance impacts the timing constraints. Query and update operations are slower as URL datasets increase in size. The indexes need to be tuned, and the database maintenance needs to be planned in a manner that does not conflict with synchronization windows. The system needs to scale to accommodate large amounts of data without giving up on response times.
Typical Testing Challenges in Automated Data Synchronization
When you are working with Phishtank’s API for automated testing purposes, rate limits can be your worst nightmare. Most organizations use robust throttling to ensure abuse is not possible, and Phishtank is no different. Your test suite may function beautifully with a tiny dataset, but the moment you scale to mimic real-world loads, you will surely hit those walls.
The problem especially becomes serious in continuous integration cycles. Your automated tests must check for data synchronization several times a day, yet API limits frequently limit you to only a few hundred requests an hour. This makes your test run time blow out beyond respectable limits, hurting development cycles and even hiding key problems.
Bandwidth limits impose an additional level of difficulty. Phishtank URL information can be large, particularly when synchronizing full datasets each hour. High network traffic during busy times can reduce your data transfer speeds, resulting in timeouts on your test cases. Such limitations don’t merely slow tests down – they can lead to false negatives where genuine synchronization processes fail because of network limitations instead of actual application defects.
Intelligent testing strategies include the use of exponential backoff algorithms and test design that gracefully respond to rate limit errors. You’ll also want to look at using subsets of test data during development cycles and leaving full dataset testing for certain validation runs.
Data Integrity Verification in Multiple Synchronization Cycles
Data consistency in multiple hourly synchronization cycles poses special verification challenges. Phistank data, unlike static datasets, is constantly changing – URLs are added, deleted, or updated with fresh threat classifications. Your testing framework needs to take this dynamic nature into consideration and ensure that data transformations and storage operations are integrity-sustaining.
Its complexity increases when you factor in that synchronization cycles can get interleaved or delayed. What if your hour-long sync is taking 75 minutes because of network degradation? How do you ensure that duplicate records are not being created or that valid updates are not being over-written? These situations call for advanced testing methodologies that exceed mere before-and-after validation.
Checksum verification gets complex with changing datasets. Hash-based integrity verification is effective for static datasets but won’t work when you have legit data modifications. You require test tools that can tell the difference between legit data evolution and corruption or sync errors. That often means implementing timestamp tracking, field-level validation, and delta compare algorithms.
Version conflicts are another key testing issue. When you have several synchronization processes executing concurrently or when the network is causing retry mechanisms to trigger, you can get competing versions of data. Your test environment must mimic these race conditions and ensure that your conflict resolution schemes function under load as they should.
Network Latency Variations Disrupting Consistent Test Results
Network delay introduces one of the most unreliable variables in test automation environments. Your synchronization step can take 30 seconds at night but several minutes when the network is congested. This inconsistency makes it all but impossible to set reliable test baselines and may cause flaky tests that pass or fail due to network factors instead of code quality.
Geographic distribution adds another wrinkle. If your application serves global users, network latency varies dramatically based on server locations and routing paths. A test that validates 5-second response times from your primary data center might consistently fail for users connecting from distant regions. Your testing strategy must account for these geographical realities and establish appropriate tolerance thresholds.
Intermittent connectivity problems present special difficulties for automated testing. Short network outages lasting a few seconds can lead to synchronization errors, but these same outages may not happen during your test runs. These conditions lead to blind spots in which your test suite passes reliably, but production systems fail intermittently, and are hard to reproduce in test environments.
Timeout settings are now essential considerations. Make them too low, and valid operations during ordinary network oscillation cease. Make them too high, and real issues take too long to catch up with, causing cascading failures in your sync pipe.
Memory and Storage Constraints In High-Volume Data Processing
High-volume data processing strains system resources to the breaking point, presenting challenging test cases that are hard to model in development environments. Phishtank databases may hold millions of URL entries, and processing this amount brings out memory leaks, storage bottlenecks, and performance degradation that may never be surfaced using smaller test databases.
Memory management is especially tricky when your synchronization process must keep track of state over several operations. Loading whole data sets into memory to process them may be fine in development but will lead to out-of-memory conditions in production systems with multiple processes occurring concurrently. Your testing harness must have techniques for verifying memory-efficient processing algorithms and catching possible memory leaks prior to their effects on production systems.
Storage I/O limitations often become the hidden bottleneck in data synchronization testing. While your application might handle the data processing logic perfectly, disk write operations can become the constraining factor when dealing with millions of URL records. Testing these scenarios requires simulating high-volume write operations and validating that your storage systems can handle the sustained throughput requirements.
Garbage collection stoppages in managed languages introduce further complexity. Big dataset processing will initiate long garbage collection cycles that freeze your app for several seconds, giving way to possible timeout errors in supporting systems. Your testing process must consider these stoppages and ensure your synchronization processes continue to be robust during these unavoidable delays.
Resource contention testing is necessary when many synchronization processes or other applications are sharing the same infrastructure. Competition between CPU, memory, and storage resources can significantly affect performance characteristics, so it is important to test system behavior under realistic loads.